





我们已经使用DolphinScheduler做为我们的调度框架很久了。但是之前总是监控到出现重复的调度的问题,此文记录排查重复调度问题的全过程。
注:本文使用的DolphinScheduler 3.1.1的版本。
数据库使用的Tidb数据库,版本6.5.0,数据库的隔离级别是默认的RR(Read Committed)。
Quartz版本为2.3.2,存储模式为JDBC。使用的CronTrigger,设置了org.quartz.jobStore.acquireTriggersWithinLock=true
先说结论。Tidb和Mysql在RR隔离级别下,开启事务后,创建Read view的时机不同,导致Tidb会出现Quartz重复调度的问题。
一、问题发生
前一段时间,客户给我们报了重复调度的问题。
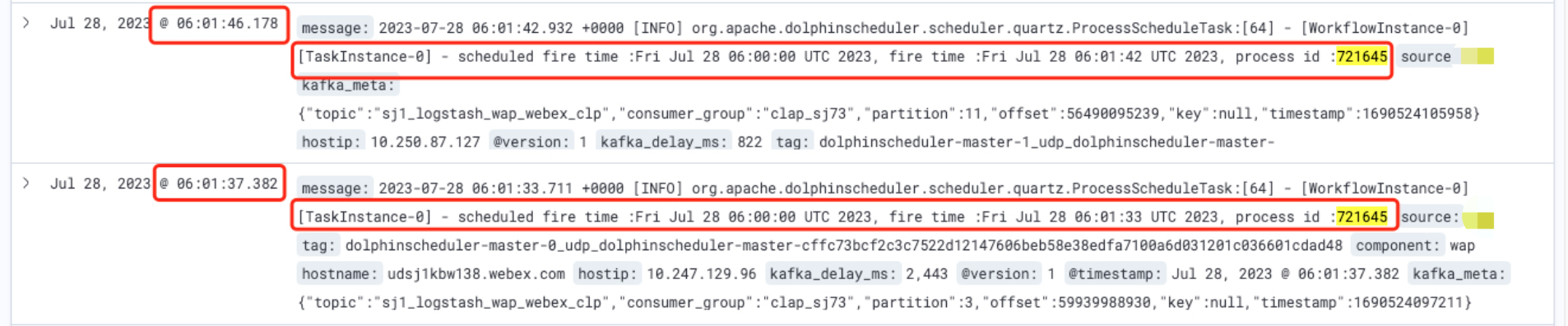
可见下图,同名同调度时间的任务被执行了两次,id相差1。还不是个偶发情况,基本每一到两天都能会出现。对于调度框架,出现重复调度的问题是不可接受的。

二、问题定位
第一步就是定位问题,DolphinScheduler的底层调度框架是Quartz。首先要明确问题的原因,是Quartz的问题还是DolphinScheduler的问题。通过排查日志,可以看到是Quartz这边的问题。
那问题很明确了,Quartz这边出现了重复调度,当时就觉得很奇怪,因为这个框架非常稳定了,上一次发版本还是在Oct 24, 2019。很多调度框架的底层使用的都是Quartz,比如XXL-Job等。但是日志这边确实很清晰的看出来确实Quartz重复触发了同一个任务。
网上关于Quartz重复调度的问题的解决方案都是加锁
设置 org.quartz.jobStore.acquireTriggersWithinLock=true
但是DolphinScheduler这边默认在配置文件中就已经设置了这个参数。
比较棘手,不太好排查。网上也没有太多相关的资料。
当时怀疑是不是数据库的问题,比如锁失效,多个线程拿到了同一把锁,说实话感觉这个可能性不大,但是确实没想到其他的可能。
于是就先看Quartz的源码和调度逻辑,这种问题一般需要了解更多的底层知识才能发现问题。在看源码的时候也看到了这么一篇博客,写的非常清晰,有非常好的参考价值,非常感谢作者。
我们首先讲解一下Quartz里面一些关于调度的概念,后面会用到。
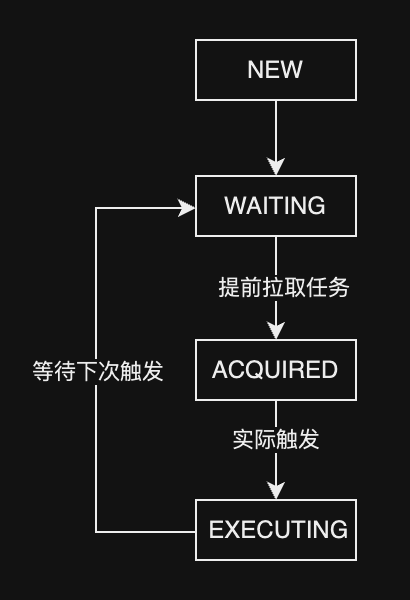
- Quartz核心调度主要是QRTZ_TRIGGERS这张表。Quartz把一次调度称之为一次Fire。QRTZ_TRIGGERS这张表里有几个比较核心的字段,TRIGGER_NAME(调度任务名)、PREV_FIRE_TIME(上次调度时间)、NEXT_FIRE_TIME(下次调度时间)、TRIGGER_STATE(当前状态)。
- QRTZ_FIRED_TRIGGERS,这张表存储的正在触发的调度信息。
状态正常的Tigger状态变更流程图:
Quartz调度过程简化
- 加锁
- 获取将要fire的triggers列表,这里有一个概念,比如当前时间是9.59,他可能会获取下次调度时间为9.57-10.02之间的trrigers,防止漏调度的问题
- 更新QRTZ_TRIGGERS的状态从WAITING->ACQUAIRED
- 将trigger信息insert进QRTZ_FIRED_TRIGGERS表,状态为ACQUAIRED
- 释放锁
等到真正开始调度
- 加锁
- 检查QRTZ_TRIGGERS状态是否为ACQUAIRED
- 如果是,QRTZ_FIRED_TRIGGERS状态更改为EXECUTING
- 更新QRTZ_TRIGGERS的next_fire_time
- 将QRTZ_TRIGGERS状态更新为WAITING
- 释放锁
1、开启MVCC日志
在看源码的同时,也联系DBA是否可以保持DB这边所有的sql以供排查。
DBA这边反馈保持所有的sql会占据大量的磁盘空间,但是可以先开启MVCC日志,也就是可以切换到不同的时间点,去查看当时数据库里面的状态。也很有用。
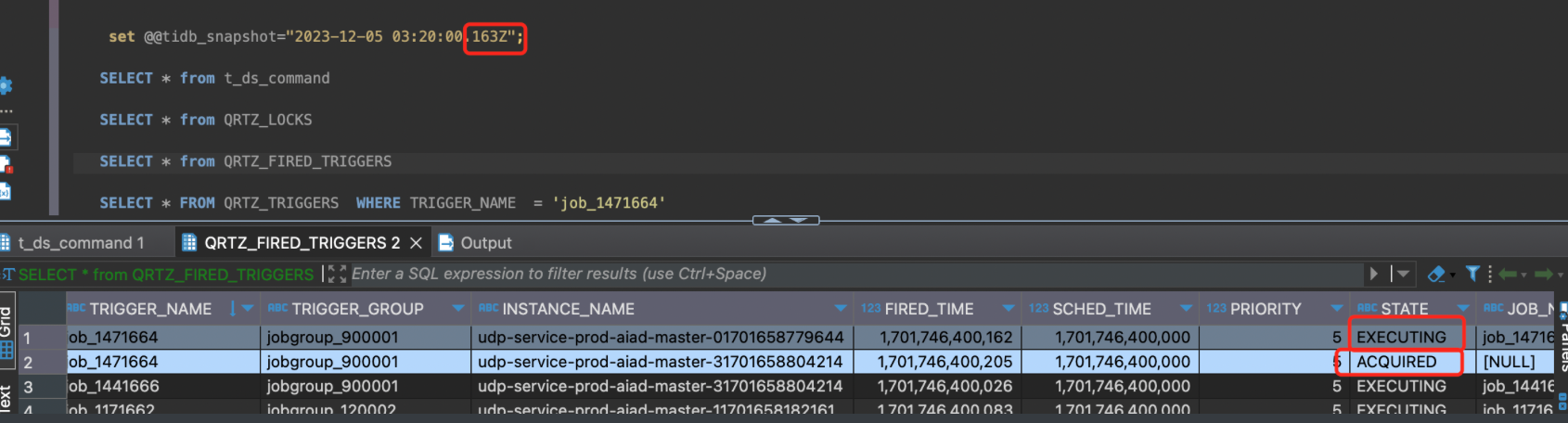
进过排查可以看见,针对于同一条调度,QRTZ_FIRED_TRIGGERS出现了两条记录,更加印证了重复调度是由于Quartz引起的。
但是拿不到具体执行了哪些sql,单纯看MVCC没有太多的价值。
2、开启全量日志
再次跟DBA沟通后,给我们搭建了一个新集群,仅供测试使用,可以开启全量日志。
有了全量日志就非常方便排查了。
1 | [2024/02/28 18:45:20.141 +00:00] [INFO] [session.go:3749] [GENERAL_LOG] [conn=2452605821289251623] [user=udp@10.249.34.78] [schemaVersion=421] [txnStartTS=448042348020498438] [forUpdateTS=448042348020498438] [isReadConsistency=false] [currentDB=udp] [isPessimistic=true] [sessionTxnMode=PESSIMISTIC] [sql="INSERT INTO t_ds_process_instance ( process_definition_code, process_definition_version, state, state_history, recovery, start_time, run_times, name, host, command_type, command_param, task_depend_type, max_try_times, failure_strategy, warning_type, warning_group_id, schedule_time, command_start_time, executor_id, is_sub_process, history_cmd, process_instance_priority, worker_group, environment_code, timeout, tenant_id, next_process_instance_id, dry_run, restart_time ) VALUES ( 12316168402080, 1, 1, '[{\"time\":\"2024-02-28 18:45:20\",\"state\":\"RUNNING_EXECUTION\",\"desc\":\"init running\"},{\"time\":\"2024-02-28 18:45:20\",\"state\":\"RUNNING_EXECUTION\",\"desc\":\"start a new process from scheduler\"}]', 0, '2024-02-28 18:45:20.007', 1, 'shell-1-20240228184520007', 'udp-service-dev-aiad-master-1.udp-service-dev-aiad-master-headless.wap-udp-dev.svc.aiadgen-int-1:5678', 6, '{\"schedule_timezone\":\"Asia/Shanghai\"}', 2, 0, 1, 0, 0, '2024-02-28 18:43:08.0', '2024-02-28 18:45:17.0', 810004, 0, 'SCHEDULER', 2, 'default', -1, 0, -1, 0, 0, '2024-02-28 18:45:20.007' )"] |
通过日志我们可以看到出现了重复调度,预计调度时间是 2024-02-28 18:43:08.0
我们需要找出跟调度相关的日志,QRTZ_FIRED_TRIGGERS和QRTZ_TRIGGERS。
第一次调度相关日志:
1 | [2024/02/28 18:45:08.250 +00:00] [INFO] [session.go:3749] [GENERAL_LOG] [conn=2452605821289251625] [user=udp@10.249.34.78] [schemaVersion=421] [txnStartTS=448042343682015234] [forUpdateTS=448042344638840833] [isReadConsistency=false] [currentDB=udp] [isPessimistic=true] [sessionTxnMode=PESSIMISTIC] [sql="UPDATE QRTZ_TRIGGERS SET JOB_NAME = 'job_1201640', JOB_GROUP = 'jobgroup_1200004', DESCRIPTION = null, NEXT_FIRE_TIME = 1709145788000, PREV_FIRE_TIME = 1709145784000, TRIGGER_STATE = 'WAITING', TRIGGER_TYPE = 'CRON', START_TIME = 1709114081000, END_TIME = 4861267200000, CALENDAR_NAME = null, MISFIRE_INSTR = 1, PRIORITY = 5 WHERE SCHED_NAME = 'DolphinScheduler' AND TRIGGER_NAME = 'job_1201640' AND TRIGGER_GROUP = 'jobgroup_1200004'"] |
第二次调度相关日志:
1 | [2024/02/28 18:45:18.454 +00:00] [INFO] [session.go:3749] [GENERAL_LOG] [conn=2452605821289251605] [user=udp@10.249.34.78] [schemaVersion=421] [txnStartTS=448042345936453636] [forUpdateTS=448042347509317637] [isReadConsistency=false] [currentDB=udp] [isPessimistic=true] [sessionTxnMode=PESSIMISTIC] [sql="SELECT TRIGGER_NAME, TRIGGER_GROUP, NEXT_FIRE_TIME, PRIORITY FROM QRTZ_TRIGGERS WHERE SCHED_NAME = 'DolphinScheduler' AND TRIGGER_STATE = 'WAITING' AND NEXT_FIRE_TIME <= 1709145941638 AND (MISFIRE_INSTR = -1 OR (MISFIRE_INSTR != -1 AND NEXT_FIRE_TIME >= 1709145618319)) ORDER BY NEXT_FIRE_TIME ASC, PRIORITY DESC"] |
可以看出呈现线程关系,也就是第一次调度彻底结束之后,出现了第二次调度。
比较疑惑的点在于第一次调度后已经更新了QRTZ_TRIGGERS的next fire time,但是第二次调度在select 之后触发的调度跟第一次调度的调度时间相同。
我们拿不到sql的执行结果,但是通过日志分析,第二次调度在执行select 获取需要调度的任务时,返回的结果跟第一次调度时返回的结果相同。
非常奇怪。当时怀疑是不是数据库的主从同步有问题,导致第二次调度获取的数据是更新前的数据。
但是通过mvcc查看:
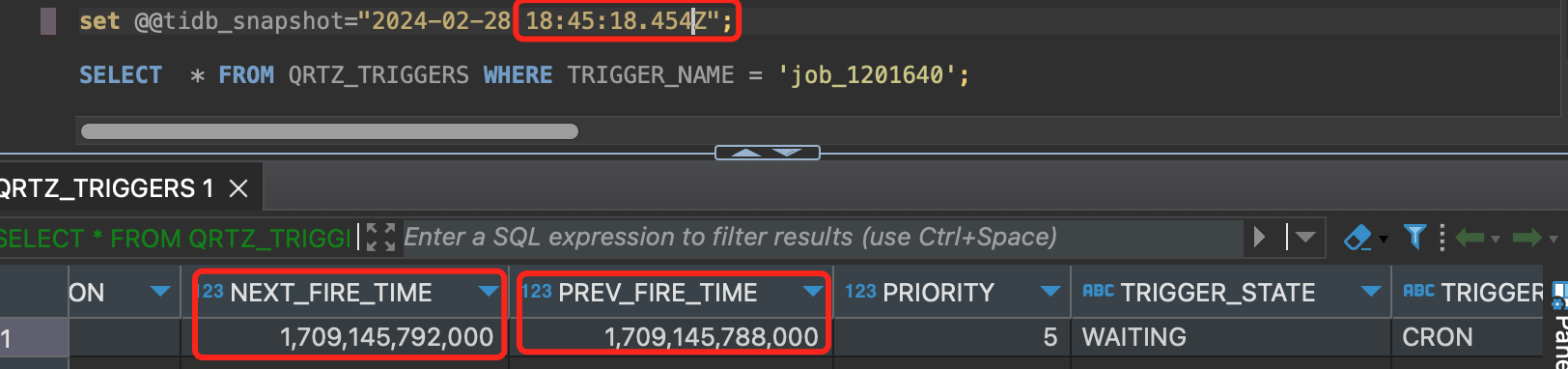
可以明显的看出来,第二次调度的时候,数据库的值更新过的,不存在主从同步的问题。
并且从日志来看,是串行执行的,也就是获取锁没问题,说到获取锁,那么看看加锁释放锁是怎么个流程。
3、查看锁记录
conn可以简单理解为进程号。结果出乎意料,第二次调度的进程在45分11秒就尝试获取锁了,45分18秒才获取到锁。中间等待了7秒。
1 | [2024/02/28 18:45:11.772 +00:00] [INFO] [session.go:3749] [GENERAL_LOG] [conn=2452605821289251605] [user=udp@10.249.34.78] [schemaVersion=421] [txnStartTS=0] [forUpdateTS=0] [isReadConsistency=false] [currentDB=udp] [isPessimistic=true] [sessionTxnMode=PESSIMISTIC] [sql="SELECT * FROM QRTZ_LOCKS WHERE SCHED_NAME = 'DolphinScheduler' AND LOCK_NAME = 'TRIGGER_ACCESS' FOR UPDATE"] |
那第一次调度进程什么拿到锁的,于是梳理了一下两个进程申请释放锁的关系。
第一次调度的进程号简称为625,第二次调度的进程号简称为605。
18:45:09.427 625 申请锁
18:45:11.772 605 申请锁 -> 阻塞
18:45:12.210 625拿到锁
625 执行调度逻辑
625 18:45:16.730 执行完,更新triggers 表
18:45:17.287 625释放锁
18:45:17.928 625申请锁
18:45:18.363 605拿到锁
605 执行调度逻辑
看到这里,就有个猜想,605在拿到锁的时候查询QRTZ_TRIGGERS的结果跟625是相同的。
4、复现问题
那我们可以复现这个流程。
首先创建表。
1 | CREATE TABLE `QRTZ_LOCKS` ( |
随后开启两个会话,按照如下顺序测试
Tidb
| Process1 | Process2 |
|---|---|
| start TRANSACTION; | |
| start TRANSACTION; | |
SELECT * FROM QRTZ_LOCKS WHERE SCHED_NAME = ‘DolphinScheduler’ AND LOCK_NAME = ‘TRIGGER_ACCESS’ FOR UPDATE; 当前读 |
|
SELECT * FROM QRTZ_LOCKS WHERE SCHED_NAME = ‘DolphinScheduler’ AND LOCK_NAME = ‘TRIGGER_ACCESS’ FOR UPDATE; 当前读 |
|
UPDATE t_ds_version set version = ‘2’ where 1 = 1; |
|
| commit; | |
| select * from t_ds_version; `快照读1 | |
version = 1 |
Process2的select * from t_ds_version;读取到的version=1。
而同样的操作在MySQL上执行时,Process2读取到的却是version=2。
该问题是因为MySQL和Tidb开启事务时创建Read view的时机不同导致的。
Mysql 在RR隔离级别下,同一个事务中的
第一个快照读才会创建Read View,之后的快照读读取的都是同一个Read View。
没有搜到Tidb对于这块的相关文档,但是通过现象来看则是在开启事务的同时就创建了Read View。 关于Mysql的相关文档可以参考MySQL InnoDB的MVCC实现机制。
那说明应该就是这个差别导致了重复调度的问题。
5、问题复盘
我们假设一种情况,详见下图。
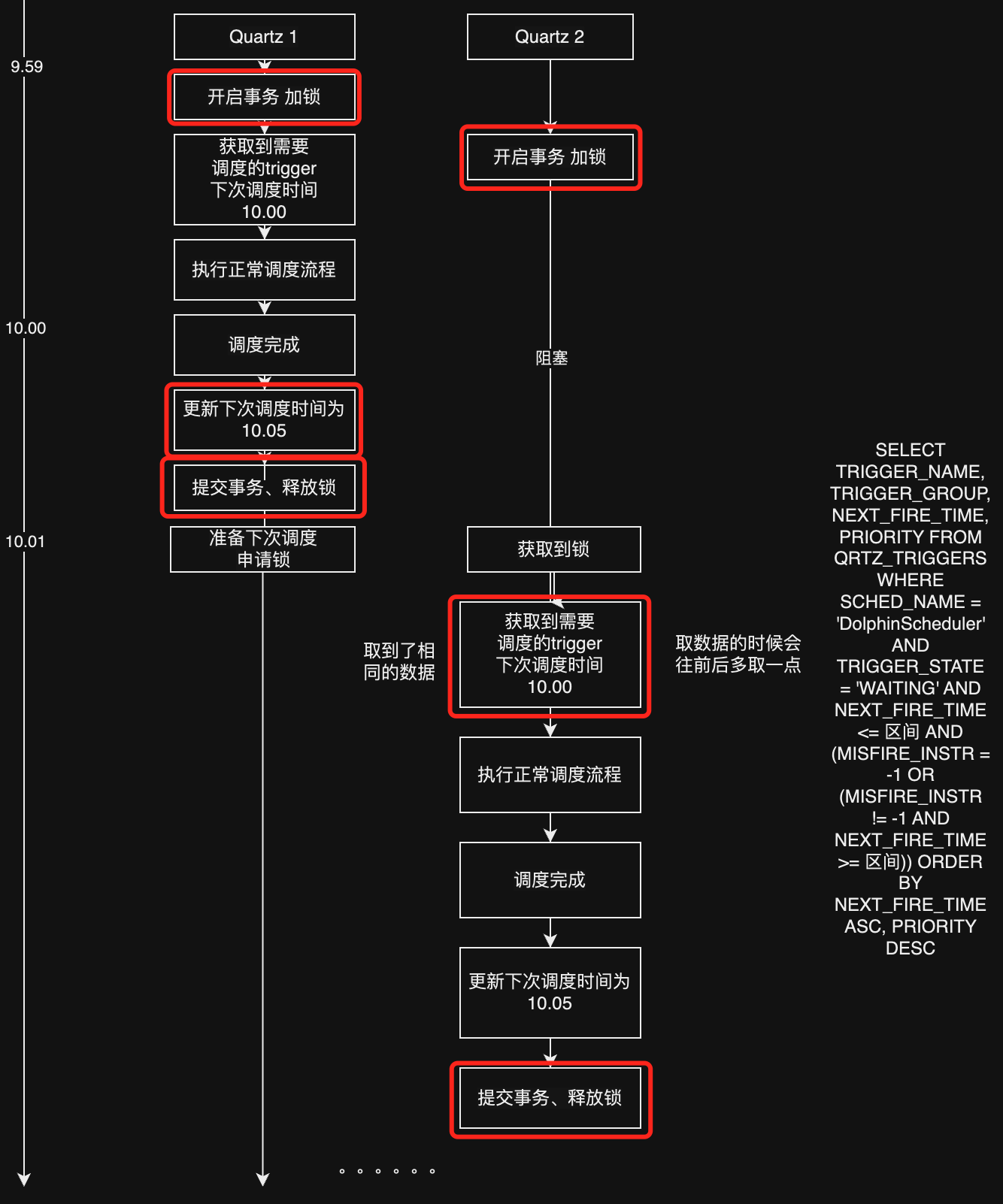
两个服务器一先一后开启事务,然后抢占锁,拿到锁后执行调度的逻辑。
如同所示,就出现了重复调度的情况。只看红框里面的逻辑,就跟最上面我们模拟在Tidb和Mysql中执行的一样,服务器2在Tidb数据库的情况下,拿到锁之后读取的是9.59时间下的Read View,所以也正常触发了应该10.00调度的任务。出现了重复的调度的情况。甚至可能出现重复调度三次四次的情况,如果在极其巧合的情况下。
三、解决方案
切换Mysql数据库,或者Tidb数据库更改到RC隔离级别。
关于为什么Tidb和Mysql在RR隔离级别下有区别,可以Track